Grace Hopper Has Entered Full Production & Announcing DGX GH200 AI Supercomputer

NVIDIA has launched a series of AI-centric announcements confirming that its Grace Hopper “superchip” has entered full production. Combining the Grace CPU and Hopper H100 GPU, the Grace Hopper is designed to be his NVIDIA answer to customers who need a more tightly integrated CPU + GPU solution for their workloads, especially AI models. I’m here.
Grace Hopper is NVIDIA’s effort to leverage both existing strengths in the GPU space and new initiatives in the CPU space to deliver a semi-integrated CPU/GPU product unlike any offered by top-line competitors. Yes, it has been under development for several years. With its traditional dominance in the GPU space, NVIDIA has essentially gone in the opposite direction, combining its GPU technology with other types of processors (CPUs, DPUs, etc.) to access markets that benefit from GPU acceleration. efforts have been made, but it is unlikely that a fully discrete GPU will ever make it to the market. Not the best solution.
| NVIDIA Grace Hopper Specifications | |||
| Grace Hopper (GH200) | |||
| CPU core | 72 | ||
| CPU architecture | Arm Neoverse V2 | ||
| CPU memory capacity | <=480GB LPDDR5X (ECC) | ||
| CPU memory bandwidth | <=512GB/s | ||
| GPU SM | 132 | ||
| GPU Tensor Cores | 528 | ||
| GPU architecture | hopper | ||
| GPU memory capacity | <=96GB | ||
| GPU memory bandwidth | <=4TB/s | ||
| GPU to CPU interface | 900GB/s NV Link 4 |
||
| TDP | 450W to 1000W | ||
| manufacturing process | TSMC 4N | ||
| interface | super chip | ||
In this first NVIDIA HPC CPU + GPU mashup, Hopper GPUs are the known side of the equation. NVIDIA has detailed Hopper’s architecture and performance expectations over a year ago, even though it’s only started shipping quite a bit so far this year. Based on his GH100 GPU with 80B transistors, the H100 delivers FP16 matrix math throughput of just under 1 EFLOPS for AI workloads and 80GB of HBM3 memory. The H100 itself is already a huge success. Thanks to the explosion of ChatGPT and other generative AI services, NVIDIA is already selling everything it can manufacture. However, NVIDIA is still working to enter markets where workloads demand tighter CPU/GPU. integration.
Paired with the H100 is NVIDIA’s Grace CPU. This itself just went into full production a few months ago. The Arm Neoverse V2 based chip is powered by his 72 CPU cores with up to 480GB of his LPDDR5X memory. The CPU core itself is quite interesting, but the even bigger change with Grace is his NVIDIA decision to co-package the CPU with his LPDDR5X rather than using slotted DIMMs. On-package memory allowed NVIDIA to use both high-clock and low-power memory at the expense of scalability. This sets Grace apart from other HPC class CPUs on the market. Given the emphasis on both the size of the dataset and the memory bandwidth required to shuffle that data, this is potentially a huge problem for large language model (LLM) training.
Data shuffling helps define a single Grace Hopper board as more than just a CPU and GPU stuck on the same board. NVIDIA has included NVLink support (NVIDIA’s proprietary high-bandwidth chip interconnect) in the Grace, so Grace and Hopper have a much faster interconnect than traditional PCIe-based CPU+GPU setups. The resulting NVLink chip-to-chip (C2C) link provides 900 GB/s of bandwidth between the two chips (450 GB/s in each direction), and the hopper can read and write to Grace even faster than it can read or write. You will be able to communicate. own memory.
The resulting board, which NVIDIA calls the GH200 a “superchip,” is intended to be NVIDIA’s answer to the AI and HPC markets in the next product cycle. For customers who want more local CPU than a traditional CPU+GPU setup, or perhaps more strictly, customers who want more near-local memory than a standalone GPU can have, Grace Hopper is NVIDIA’s answer to this. The most comprehensive computing offering ever. On the other hand, given NVIDIA’s current use of AI vendors, there is some uncertainty as to how widespread Grace’s dedicated (CPU only) superchip will be, and ultimately Grace Hopper will make Grace best. you may end up seeing. likewise.
According to NVIDIA, systems incorporating the GH200 chip are expected to launch later this year.
DGX GH200 AI Supercomputer: Grace Hopper Goes Straight To The Big Leagues
Meanwhile, the Grace Hopper isn’t technically finished yet, but NVIDIA is already working on building the first DGX system around this chip. However, in this case, the name of the system “DGX” might be a bit misleading. Unlike his other DGX systems, it is not a single node, but a full multi-rack compute cluster. That’s why NVIDIA calls it a “supercomputer.” “
At a high level, the DGX GH200 AI supercomputer is a complete turnkey 256-node GH200 cluster. A single DGX GH200 that spans about 24 racks contains 256 GH200 chips, 256 Grace CPUs and 256 H100 GPUs, and a It also includes all the network hardware you need. Cumulatively, a DGX GH200 cluster offers 120 TB of CPU-attached memory, plus 24 TB of GPU-attached memory, and a total of 1 EFLOPS of FP8 throughput with sparsity.

Look closely: it’s not a server node – it’s a rack of 24 servers
Linking the nodes together is a two-tier network system built around NVLink. 96 local L1 switches provide instant communication between GH200 blades and another 36 L2 switches provide layer 2 connectivity linking the L1 switches. And if scalability isn’t enough, the InfiniBand present in the cluster as part of NVIDIA’s use of ConnectX-7 network adapters can be used to further scale up the size of the DGX GH200 cluster.
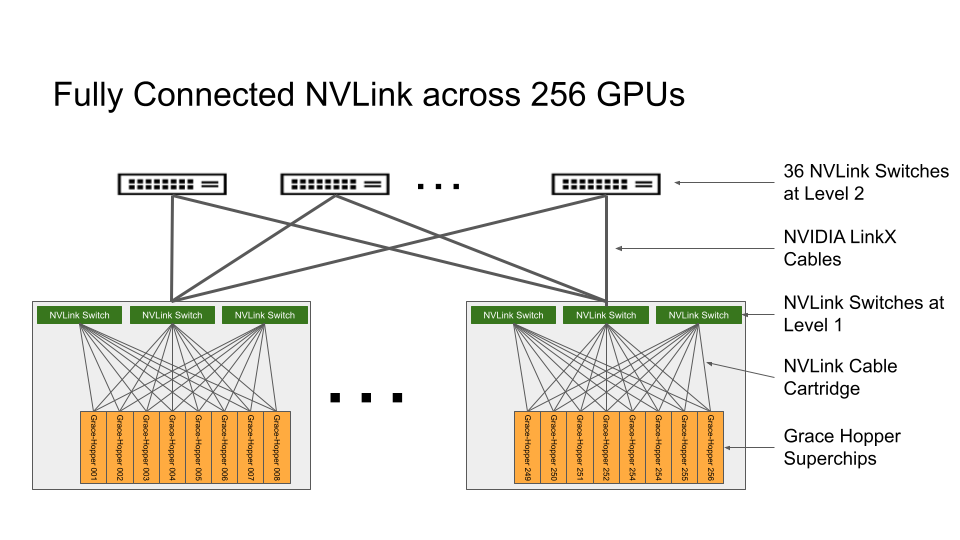
The target market for large silicon clusters is training large AI models. NVIDIA relies heavily on existing hardware and toolsets in the field, combining the massive amount of memory and memory bandwidth provided by a 256-node cluster to power some of the largest AI models can. The recent explosion of interest in large language models has revealed how much memory capacity is a limiting factor. So this is his NVIDIA attempt to provide a single-vendor integrated solution for customers, especially those with large models.
While NVIDIA doesn’t explicitly disclose it, as evidence that they’ve gone all-out for their DGX GH200 cluster, the memory capacity NVIDIA has listed seems to suggest that NVIDIA ships a regular H100 GPU as part of the system. It shows that you are not alone. Rather, they’re using the 96GB model, which has limited stock and is usually disabled 6th HBM3 memory stack enabled. So far NVIDIA has only offered these H100 variants in a handful of offerings (specialized H100 NVL PCIe cards and now some GH200 configs) so the DGX GH200 has him using NVIDIA’s best silicon is scheduled to be adopted.
Of course, don’t expect NVIDIA supercomputers to come cheap. NVIDIA didn’t announce the pricing not so long ago, but based on the pricing of the HGX H100 boards ($200k for 8 H100s on carrier boards), a single DGX GH200 could easily be priced in the 8 figures. It will be somewhere in the first half. Suffice it to say that the DGX GH200 is aimed at a fairly specific subset of enterprise customers who have large model training needs at scale and can afford to pay for a complete turnkey solution.
Ultimately, though, the DGX GH200 is not just a high-end system for NVIDIA to sell to its affluent customers, but a blueprint for helping hyperscaler customers build their own GH200-based clusters. Also a photo. After all, building such a system is the best way to demonstrate how it works and how well it works, so NVIDIA is blazing a trail of its own in this regard. . And although NVIDIA will no doubt be happy to sell these DGX systems directly to hyperscalers, CSPs and other companies as long as they heavily adopt his GH200 (rather than the competition for example) , and it will still be. It will benefit NVIDIA.
Meanwhile, NVIDIA says the system will be available by the end of the year for the few companies that can afford the DGX GH200 AI supercomputer.




{kind=link}