
With NVIDIA’s fall GTC event in full swing, the company somehow touched on most of its core business during its keynote this morning. On the enterprise side, one of the most highly anticipated updates was the shipping status of NVIDIA’s H100 “Hopper” accelerator. After all, in Q3 he is already almost over H100 and will not be available in Q3. However, according to NVIDIA, the accelerator is in full production and the first systems are expected to ship from his OEM in October.
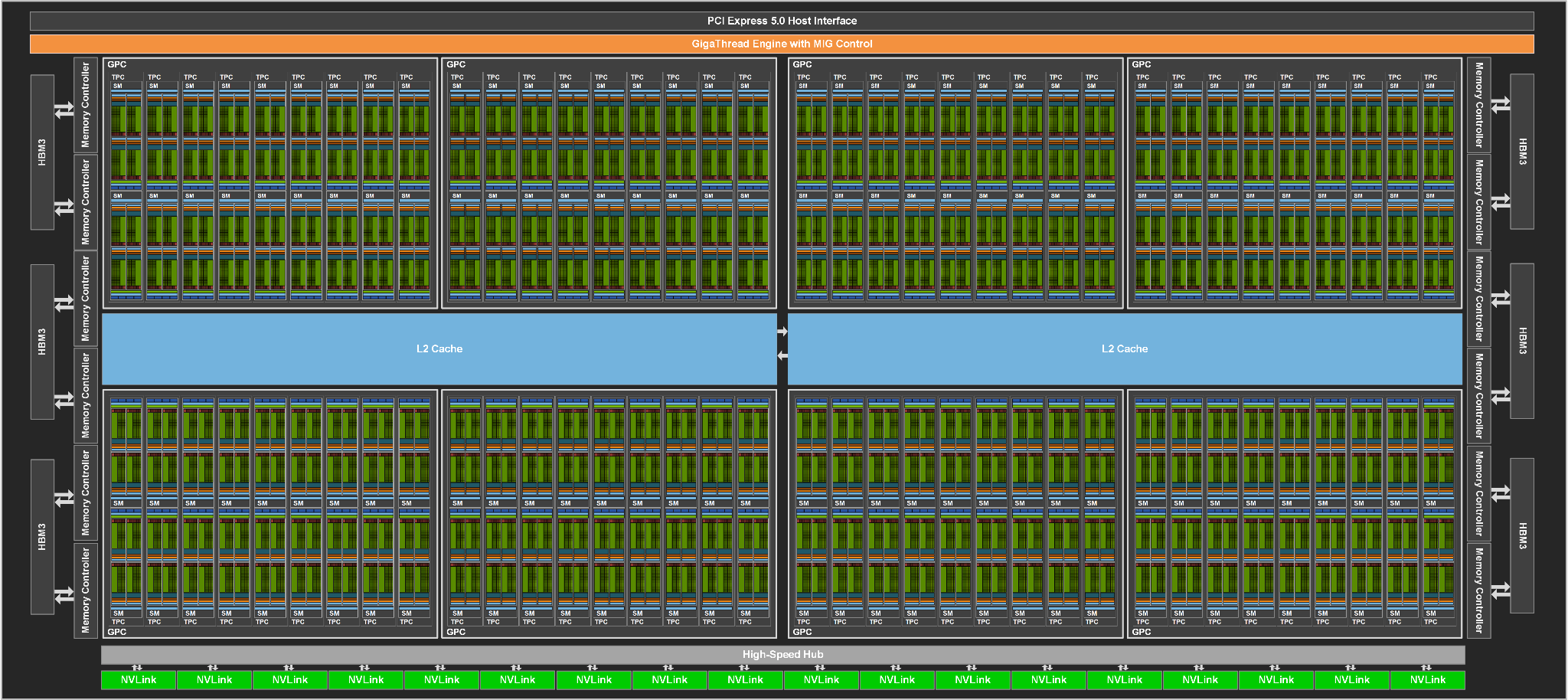
First announced at NVIDIA’s annual Spring GTC event in March, the H100 is NVIDIA’s next-generation high-performance accelerator for servers, hyperscalers, and similar markets. Based on the Hopper architecture and built on TSMC’s 4nm ‘4N’ process, the H100 is NVIDIA’s follow-up to his highly successful A100 accelerator. Among other changes, the company’s latest accelerator implements HBM3 memory, supports transform models within tensor cores, supports dynamic programming, an updated version of multi-instance GPUs with more robust isolation, and both have significantly improved computational throughput. Vector and tensor data types. Based on NVIDIA’s massive 80 billion transistor GH100 GPU, the H100 accelerator also pushes the boundaries in terms of power consumption, with a maximum TDP of 700 Watts.
Given that NVIDIA’s Spring GTC event didn’t exactly coincide with this generation’s manufacturing window, the H100 announcement earlier this year stated that NVIDIA would ship the first H100 systems in Q3. However, his NVIDIA’s latest delivery target outlined today implies that the date for Q3 is slipped. The good news is that the H100 is now in “full production,” as NVIDIA says. The bad news is that it looks like production and integration didn’t start on time. At this point, the company doesn’t expect the first production systems to reach customers until October, the start of the fourth quarter.
Throwing a further spanner at the problem, the order in which systems and products are deployed is essentially reversed from NVIDIA’s usual strategy. Rather than starting with a system based on his SXM form factor parts with the highest performance first, NVIDIA’s partner is starting with a lower performing PCIe card. That means the first systems to ship in October will use his PCIe cards, and it won’t be until later this year that an NVIDIA partner will ship systems integrating his faster SXM cards and HGX carrier boards. .
| NVIDIA accelerator spec comparison | ||||||
| H100SXM | H100 PCIe | A100SXM | A100 PCIe | |||
| FP32 CUDA core | 16896 | 14592 | 6912 | 6912 | ||
| Tensor cores | 528 | 456 | 432 | 432 | ||
| boost clock | ~1.78GHz (Unsettled) |
~1.64GHz (Unsettled) |
1.41GHz | 1.41GHz | ||
| memory clock | 4.8Gbps HBM3 | 3.2Gbps HBM2e | 3.2Gbps HBM2e | 3.0Gbps HBM2e | ||
| memory bus width | 5120 bits | 5120 bits | 5120 bits | 5120 bits | ||
| memory bandwidth | 3TB/s | 2TB/s | 2TB/s | 2TB/s | ||
| VRAM | 80GB | 80GB | 80GB | 80GB | ||
| FP32 vectors | 60 TFLOPS | 48 TFLOPS | 19.5TFLOPS | 19.5TFLOPS | ||
| FP64 vector | 30 TFLOPS | 24 TFLOPS | 9.7TFLOPS (1/2 FP32 rate) |
9.7TFLOPS (1/2 FP32 rate) |
||
| INT8 tensor | 2000 Tops | 1600 tops | 624 Tops | 624 Tops | ||
| FP16 Tensor | 1000TFLOPS | 800 TFLOPS | 312 TFLOPS | 312 TFLOPS | ||
| TF32 Tensor | 500 TFLOPS | 400 TFLOPS | 156 TFLOPS | 156 TFLOPS | ||
| FP64 Tensor | 60 TFLOPS | 48 TFLOPS | 19.5TFLOPS | 19.5TFLOPS | ||
| interconnect | NVLink4 18 links (900GB/s) |
NVLink4 (600GB/s) |
NVLink3 12 links (600GB/s) |
NVLink3 12 links (600GB/s) |
||
| GPUs | GH100 (814mm2) |
GH100 (814mm2) |
GA100 (826mm2) |
GA100 (826mm2) |
||
| number of transistors | 80B | 80B | 54.2B | 54.2B | ||
| TDP | 700W | 350W | 400W | 300W | ||
| manufacturing process | TSMC 4N | TSMC 4N | TSMC 7N | TSMC 7N | ||
| interface | SXM5 | PCIe 5.0 (dual slot) |
SXM4 | PCIe 4.0 (dual slot) |
||
| architecture | hopper | hopper | Ampere | Ampere | ||
NVIDIA’s flagship DGX system, on the other hand, is usually one of the first to ship, but now it’s becoming one of the last. NVIDIA opens pre-orders for the DGX H100 system today. Delivery is expected in the first quarter of 2023 (4-7 months from now). This is good news for NVIDIA’s server partners. NVIDIA’s server partner has had to wait for NVIDIA to follow suit over the past few generations, but when his H100 as a product started shipping in systems, it’s full of power. It also means that you can’t perform. next month.
In its pre-briefing with the press, NVIDIA did not provide a detailed explanation as to why the H100 was delayed. Broadly speaking, a company representative said the delay was not due to component reasons. I mentioned. The H100 HGX/SXM systems were more complex and took longer to complete, but they are primarily plug-and-play within the general-purpose PCIe infrastructure.
The two form factors also have some important functional differences. The SXM version is the only one that uses HBM3 memory (PCIe uses HBM2e) and the PCIe version requires less working SM (114 vs 132). So there’s some room for NVIDIA to hide early yield issues, even if that’s actually a factor.

Complicating matters for NVIDIA is that the DGX H100 system is based on Intel’s Repeat Delay 4.th It is a generation Xeon Scalable processor (Sapphire Rapids) with no fully confirmed release data at this time. A less optimistic forecast is for it to launch in the first quarter. This coincides with NVIDIA’s own release date, but this could just be a coincidence, either way the lack of general availability for Sapphire Rapids means that here he’s doing NVIDIA no favors. Hmm.
Ultimately, NVIDIA’s server partners will be the first to roll out HGX systems, as NVIDIA won’t be able to ship DGX until next year. Probably going with the current generation host, or possibly when AMD’s Genoa platform is ready. Some of the companies planning to ship H100 systems include the usual suspects: Supermicro, Dell, HPE, Gigabyte, Fujitsu, Cisco and Atos.
Meanwhile, for customers who want to try the H100 before buying the hardware, the H100 is now available on NVIDIA’s LaunchPad service.
Finally, while we’re talking about the H100, NVIDIA is using this week’s GTC to announce licensing updates for the NVIDIA AI Enterprise software stack. The H100 comes with his 5 year license for the software. This is notable because a 5-year subscription is typically $8000 per CPU socket.




{kind=link}