
Artificial intelligence and deep learning are making headlines all the time these days, with ChatGPT generating bad advice, self-driving cars, artists accused of using AI, and medical advice from AI. Most of these tools rely on complex servers with lots of hardware for training, but using a trained network with inference can be done using a PC’s graphics card. But how fast can consumer GPUs do AI inference?
We benchmarked popular AI image creator Stable Diffusion on the latest Nvidia, AMD and even Intel GPUs to see how they stack up. If you’ve ever happened to get Stable Diffusion up and running on your PC, you might have some idea of its complexity (or simplicity). — it can. In a nutshell, Nvidia’s GPUs rule the roost, and most software is designed using his CUDA and the rest of his Nvidia toolset. But that doesn’t mean you can’t run Stable Diffusion on other GPUs.
I ended up using three different Stable Diffusion projects for testing. This was mainly because there was no single package that worked on all GPUs. For Nvidia we have auto 1111 webui version (opens in new tab)AMD GPUs were tested using: Shark version of Nod.ai (opens in new tab)on Intel’s Arc GPU used Stable Diffusion OpenVINO (opens in new tab)A disclaimer is in place. We didn’t code these tools, but looked for something that was easy to run (on Windows) and seemed reasonably optimized.
I’m relatively confident that the Nvidia 30 series tests do a good job of extracting near-optimal performance, especially when xformers are enabled. This gives an additional 20% performance improvement. On the other hand, the RTX 40 series’ results are a bit lower than expected, probably due to the lack of optimizations in the new Ada Lovelace architecture.
AMD’s results are also a bit mixed, but the opposite of Nvidia’s situation. RDNA 3 GPUs perform very well, while RDNA 2 GPUs look pretty mediocre. is significantly longer.
It also uses the Stable Diffusion 1.4 model instead of the newer SD 2.0 or 2.1. This was mainly because getting his SD2.1 to work on non-Nvidia hardware required a lot more work (learning how to write code to enable support). However, if you have insider knowledge of Stable Diffusion and would like to recommend another open source project that might work better than the one we used, let us know in the comments (or email Jarred ). (opens in new tab)).
image 1 of 11

The test parameters are the same for all GPUs, but the Intel version doesn’t have an option for negative prompting options (at least we couldn’t find one). The gallery above was generated using the Nvidia version, which results in a higher resolution output (because it takes longer many It will take some time to complete). This is the same prompt, but he’s targeting 2048×1152 instead of his 512×512 used for benchmarking. Here are the relevant settings:
Positive Prompt:
Post-apocalyptic steampunk city, exploration, cinematic, realistic, ultra-detailed, photorealistic maximum detail, volumetric light, (((focus))), wide angle, (((brightly lit))), (( (vegetation))), lightning, vine, destruction, devastation, wartorn, ruins
Negative Prompt:
(((bokeh))), ((fog)), (((dark))), ((monochrome)), sun, (((depth of field)))
procedure:
100
Classifier Free Guidance:
15.0
Sampling algorithm:
Some Euler variants (ancestral, discrete)
The sampling algorithm can affect the output, but does not appear to have a significant impact on performance. Auto 1111 offers most options, but the Intel OpenVINO build has no options.
Here are the test results for AMD RX 7000/6000 series, Nvidia RTX 40/30 series and Intel Arc A series GPUs: Note that each Nvidia GPU has two results. Facebook’s fast ‘xformers’ library (opens in new tab) (faster, in green).
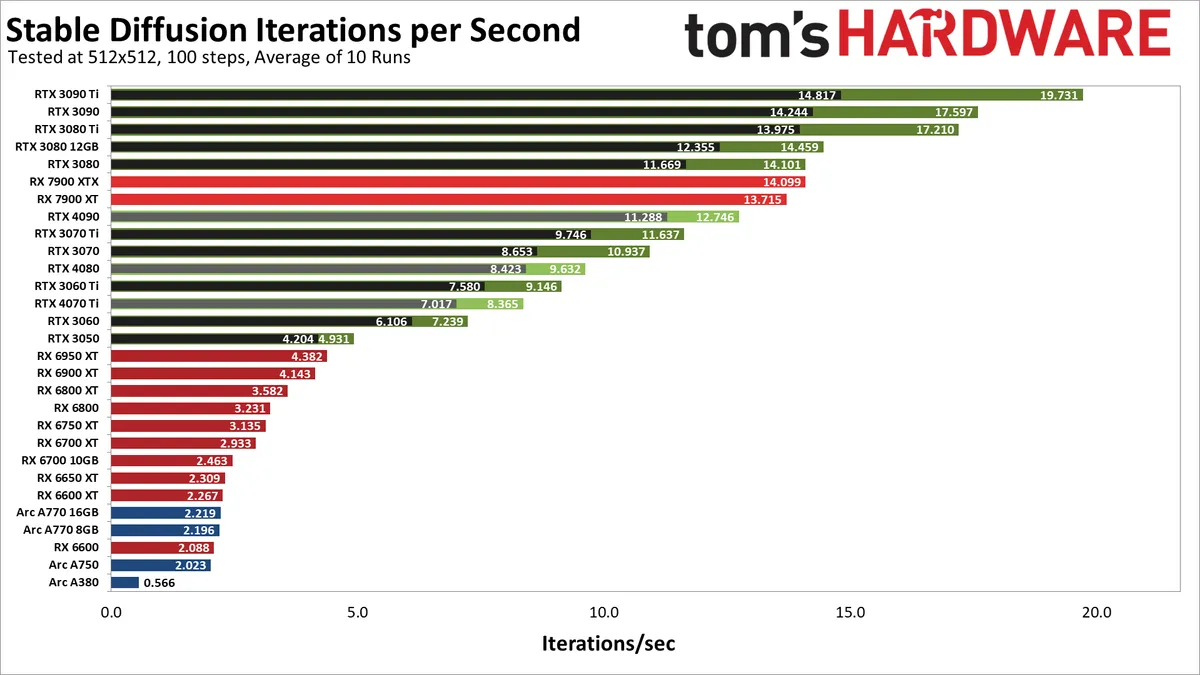
As expected, Nvidia’s GPUs offer better performance than any AMD or Intel GPU. However, there are some obvious anomalies. The fastest GPU in our initial tests is the RTX 3090 Ti, which tops out at about 20 iterations per second, or about 5 seconds per image using the configured parameters. Things drop from there, but even the RTX 3080 is basically on par with AMD’s new RX 7900 XTX, while the RTX 3050 beats his RX 6950 XT. But let’s talk about the weirdness.
First, we expected the RTX 4090 to overwhelm its competitors, but it clearly didn’t. In fact, it’s slower than AMD’s 7900 XT and slower than the RTX 3080. Similarly, the RTX 4080 sits between the 3070 and 3060 Ti, and the RTX 4070 Ti sits between the 3060 and 3060 Ti.
With the right optimizations, you can easily double the performance of your RTX 40 series cards. Similarly, given the large performance gap between the RX 7900 XT and RX 6950 XT, that optimization could also double the performance of the RDNA 2 GPU. This is a rough guess based on what we’ve seen in the GPU benchmark hierarchy, but there are some obvious oddities with these initial results.
Intel’s Arc GPUs currently give very disappointing results, especially since they support XMX (matrix) operations, which need to deliver up to 4x the throughput of regular FP32 computations. The current Stable Diffusion OpenVINO project we used could also have a lot of room for improvement. By the way, if you want to try and run SD on Arc GPU, please note that you need to edit “stable_diffusion_engine.py” file and change “CPU” to “GPU”. Otherwise, the graphics card will not be used for computation. It takes a lot of time.
back to the results. With the specified versions, Nvidia’s RTX 30 series cards perform well, AMD’s RX 7000 series cards perform well, RTX 40 series perform poorly, and RX 6000 series perform poorly. It drops significantly and Arc GPUs generally look poor. Things could change radically with updated software, and given the popularity of AI, we’d see better tuning (or a decent project that’s already tuned to give better performance). ) is expected to be a matter of time.
Again, I don’t know exactly how optimized these projects are, but it might be interesting to look at the theoretical maximum performance (TFLOPS) for different GPUs. The graph below shows the theoretical FP16 performance for each GPU, using tensor/matrix cores as needed.

Nvidia’s Tensor Cores are clearly better, at least in theory, but clearly our Stable Diffusion tests don’t match these numbers exactly. ) is up to 106% faster than the RTX 3090 Ti, but 35% slower in our tests. Also note that I assume that the Stable Diffusion project I used (Automatic 1111) doesn’t even try to take advantage of the new FP8 instructions on the Ada Lovelace GPU. This could again double the performance on the RTX 40 series.
Meanwhile, look at the Arc GPU. Those matrix cores should offer performance similar to the RTX 3060 Ti and RX 7900 XTX. The fastest A770 GPU is between the RX 6600 and RX 6600 XT, the A750 is right behind the RX 6600, and the A380 is about a quarter as fast as the A750. All of this is about a quarter of the expected performance when no XMX cores are used.
However, Arc’s proportions look about right. The A380’s theoretical computing performance is about a quarter of the A750’s. Most likely they are using shaders in full precision FP32 mode for their computations and miss some additional optimizations.
Another thing to note is that AMD’s RX 7900 XTX/XT theoretical calculations have improved significantly over the RX 6000 series. Memory bandwidth is not the critical factor. So the 7900 XTX has almost 3x the raw compute compared to his 6950 XT, so AMD’s results above aren’t entirely out of the question. Aside from the 7900 XT performing nearly as well as the XTX, raw compute should give the XTX an advantage of about 19% over the 3% we measured.
Ultimately, this is not a true statement of performance, but a snapshot in time of stable diffusion performance on AMD, Intel, and Nvidia GPUs. Full optimization brings performance closer to the theoretical TFLOPS chart, ensuring the new RTX 40 series cards don’t lag behind existing RTX 30 series parts.

This gives us one final chart with higher resolution testing. I haven’t tested all the new GPUs yet, I used Linux on a tested AMD RX 6000 series card. But it looks like a more complex target resolution of at least 2048×1152 is starting to make better use of his RTX 4090. We plan to review this topic further in the coming year.



